
Text Processing in Linux with Awk, Sed, and Grep
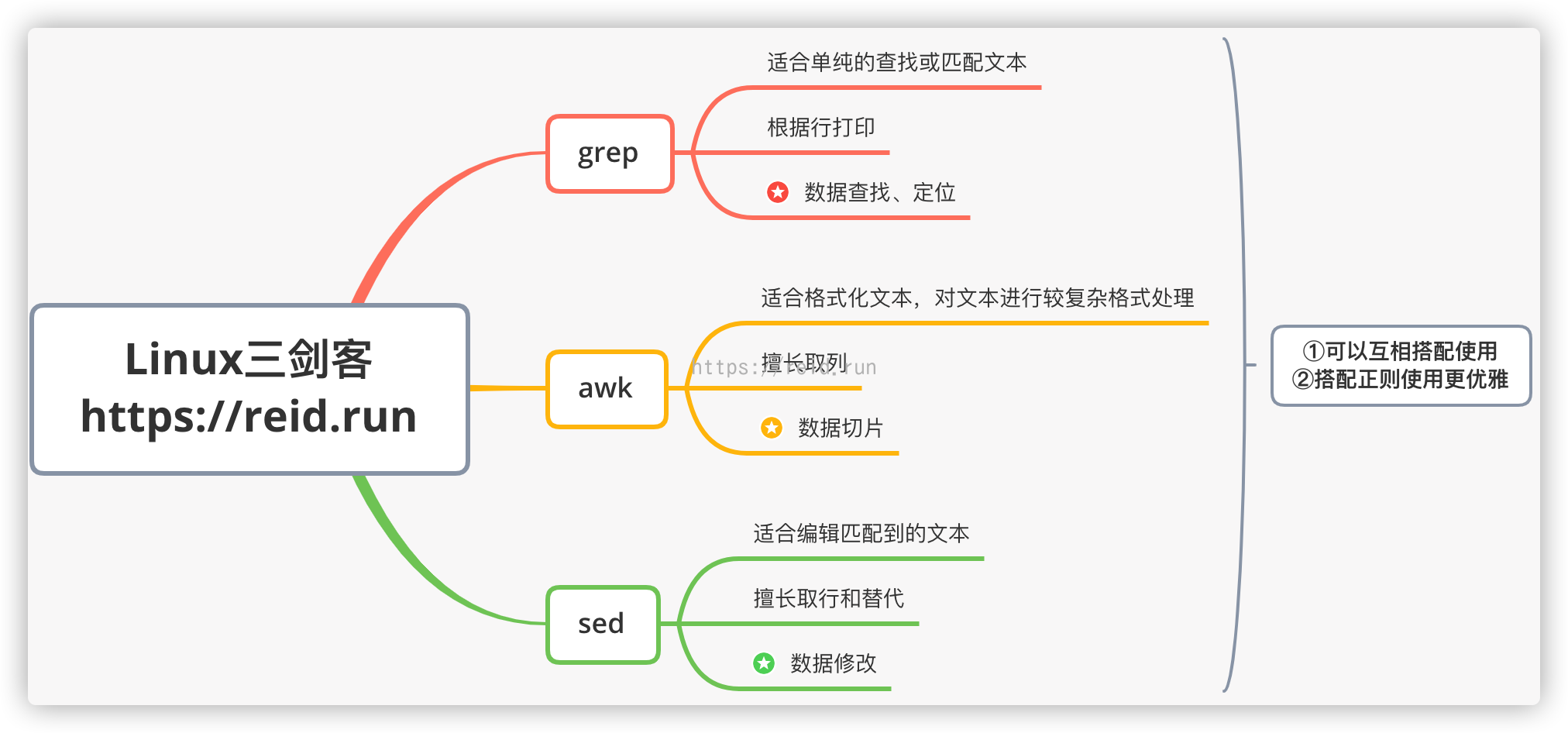
Text processing is a fundamental task in Linux, often involving tasks such as searching for patterns, modifying data, or extracting information. Linux offers a range of powerful command-line tools specifically designed for these tasks, including Awk, Sed, and Grep.
Awk (Advanced Workpattern Language)

Awk is a programming language tailored for text processing. It operates on a line-by-line basis, allowing users to extract, modify, or print data based on specified criteria. Awk scripts consist of patterns and actions, where a pattern identifies the lines of interest, and the action specifies operations to be performed on those lines.
For example, the following Awk command prints the first field of every line in a file named data.txt:
awk '{print $1}' data.txtSed (Stream Editor)
Sed is a line-oriented stream editor that allows users to transform text from standard input or a file. It offers a wide range of commands for modifying text, including search, replace, insert, and delete operations. Sed scripts are written as a sequence of commands, each operating on a specified pattern.
For example, the following Sed command replaces all occurrences of “old” with “new” in a file named text.txt:
sed 's/old/new/g' text.txtGrep (Global Regular Expression Print)
Grep is a powerful pattern-searching tool that scans text file for lines containing a specified pattern. It supports regular expressions, allowing for flexible and complex search criteria. Grep outputs only the matching lines, making it ideal for quickly identifying and filtering information.
For example, the following Grep command finds all lines in data.txt that contain the word “error”:
grep error data.txtThese three tools offer a comprehensive toolkit for text processing in Linux. Awk provides advanced pattern matching and data manipulation capabilities, Sed handles line-based transformations, while Grep excels in searching and filtering text. Understanding and utilizing these tools empowers Linux users to automate complex text processing tasks efficiently and effectively.## Text Processing In Linux With Awk, Sed, And Grep
Executive Summary
Awk, sed, and grep are powerful command-line tools for text processing in Linux environments. This article provides a comprehensive exploration of their capabilities, demonstrating how they can be used to perform various tasks with ease and efficiency. By understanding and utilizing these tools, users can unlock a new level of flexibility and control over their text data.
Introduction
Text processing is an essential aspect of many computing tasks. Whether it’s extracting data from log files, manipulating text files, or searching for specific patterns, having the right tools can make all the difference. In the Linux world, awk, sed, and grep are three indispensable tools for text processing. Each tool offers unique capabilities and can be combined to achieve even more complex tasks.
Awk
Awk is a pattern-scanning and processing language designed for manipulating text data. It is particularly useful for extracting and formatting data from large text files.
- Pattern matching: Awk allows users to define patterns that match specific lines or fields in a text file.
- Variable assignment: Matched data can be assigned to variables for further processing or manipulation.
- Conditional statements: Awk provides conditional statements (if-else) for controlling the flow of execution based on match results.
- Built-in functions: Awk comes with a丰富的库of built-in functions for tasks like string manipulation, mathematical operations, and I/O handling.
Sed
Sed is a stream editor that allows users to perform find-and-replace operations on text files. It can be used to efficiently search and modify text, making it a useful tool for tasks such as removing unwanted lines or substituting specific patterns.
- Regular expressions: Sed uses regular expressions to specify the patterns to be searched for in the text.
- Commands: Sed provides a set of commands that can be used to perform various operations on matched lines, such as deletion, insertion, or replacement.
- Flags: Flags can be used to modify the behavior of sed commands, providing additional control over the search and replace process.
- Scripts: Sed commands can be grouped into scripts for performing complex text manipulation tasks in a streamlined manner.
Grep
Grep is a pattern-searching tool that allows users to quickly find lines of text that match a specified pattern. It is often used for filtering and extracting specific information from large text files.
- Pattern matching: Grep uses regular expressions to match patterns in text files.
- Options: Grep provides various options, such as case-insensitive matching, line counting, and recursive search, for customizing the search behavior.
- Input/Output: Grep can read from standard input or specified files and output matching lines to the standard output or specified files.
- Regular expressions: Grep supports regular expressions for defining complex search patterns, allowing for precise and efficient text searching.
Conclusion
Awk, sed, and grep are powerful and versatile tools for text processing in Linux. By mastering these tools, users can dramatically improve their efficiency in handling text data. Whether it’s extracting information, manipulating files, or searching for patterns, these tools provide the necessary capabilities to tackle a wide range of tasks with ease. By combining their strengths and leveraging their unique features, users can unlock the full potential of text processing in Linux.
Keyword Phrase Tags
- Linux text processing
- Awk programming
- Sed commands
- Grep searching
- Pattern matching
I was really impressed by this article, I didn’t know there were so many tools for text processing in Linux. I will definitely try them out!
I’m not sure if this article is really that helpful. It doesn’t provide any examples of how to use these tools in practice.
This article is a great introduction to text processing in Linux. It provides a good overview of the most common tools and how they can be used.
I disagree with the author’s claim that awk is the best tool for text processing. I think sed is a more powerful and versatile tool.
This article is so informative, I can’t believe I didn’t know about these tools before. I’m going to use them to write a program that will generate random text.
Wow, this article is really groundbreaking. I’ve never heard of any of these tools before.
I tried using awk to write a program that would generate random text, but it just kept generating the same sentence over and over again. I guess I’m not a very good programmer.
I’m curious about how these tools can be used for data analysis. Can anyone give me some examples?
Here’s an example of how you can use awk to count the number of occurrences of a particular word in a text file:
I’m new to Linux, and this article has been really helpful. I’m excited to try out these tools!