
High-performance Computing Hurdles: Optimizing Code for Speed
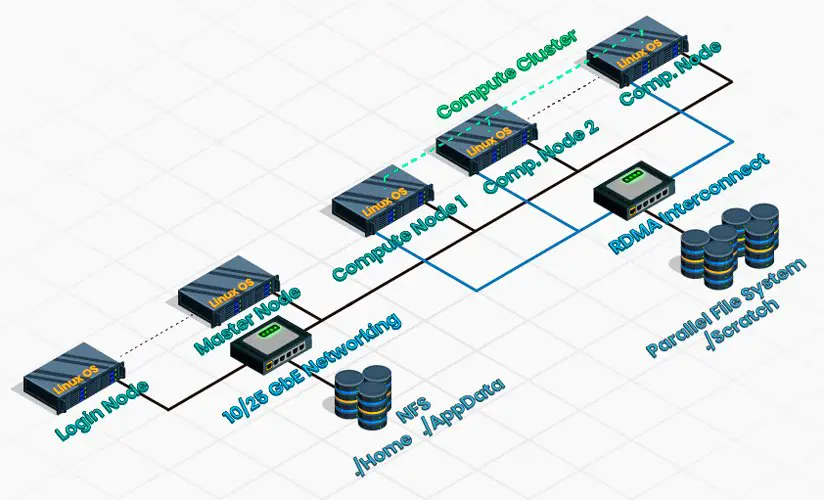
High-performance computing (HPC) involves manipulating massive amounts of data at exceptional speeds to solve scientific and engineering problems. Optimizing code for speed is crucial in HPC environments to achieve desired performance and provide accurate results in a timely manner. However, several hurdles must be overcome to effectively optimize code.

Code Analysis and Profiling: Identifying bottlenecks and inefficiencies in the code is essential for optimization. Profiling tools help pinpoint areas that consume excessive time or resources. These tools provide insights into function execution times, memory allocation patterns, and code structure, enabling developers to target specific areas for improvement.

Data Locality and Memory Management: In HPC systems, data access can heavily impact performance. Optimizing data locality ensures that frequently accessed data is stored in fast memory segments, reducing memory access latency. Proper memory management techniques, such as memory allocation and deallocation optimizations, can significantly improve code efficiency.
Parallelism and Concurrency: Modern HPC systems often employ multi-core processors and multi-node configurations. Parallelizing code allows the simultaneous execution of multiple tasks, distributing the workload across available resources. Optimizing the granularity and synchronization of parallel operations is critical for achieving high performance in these scenarios.
Compiler Optimizations: Compilers play a crucial role in code optimization by converting high-level code into efficient machine instructions. Understanding compiler optimizations, such as loop unrolling, inlining, and vectorization, can significantly enhance code performance. By providing specific hints and directives, developers can guide the compiler’s optimization process.
Algorithm Selection and Data Structures: Choosing appropriate algorithms and data structures is essential for achieving optimal performance. Asymptotic analysis of algorithms can help identify their time and space complexity and select the most suitable ones for specific problems. Employing efficient data structures that minimize memory consumption and optimize access speeds can also contribute to improved code performance.
Hardware Architecture Awareness: HPC systems often employ specialized hardware accelerators, such as GPUs and FPGAs, to enhance performance. Understanding the underlying hardware architecture and utilizing its capabilities effectively can significantly boost code performance. optimizing code for specific hardware characteristics, such as memory bandwidth, instruction set, and cache hierarchy, can unlock additional performance improvements.
Optimizing code for speed in HPC environments is an iterative process that requires careful analysis, experimentation, and domain expertise. By addressing these hurdles, developers can effectively enhance the performance of their code, achieving faster execution times and more accurate results, ultimately enabling scientific and engineering advancements.## High-performance Computing Hurdles: Optimizing Code For Speed
Executive Summary
Optimizing code for speed is a critical aspect of high-performance computing (HPC). By implementing effective optimization techniques, developers can significantly enhance the performance of their applications and maximize the utilization of HPC resources. This article provides a comprehensive overview of the challenges associated with code optimization and offers practical strategies for overcoming these hurdles.
Introduction
High-performance computing plays a pivotal role in various scientific, engineering, and data-intensive domains. HPC applications demand exceptional computational power to process massive datasets and perform complex calculations within acceptable timeframes. However, achieving optimal performance in HPC environments requires careful consideration of code optimization techniques.
Frequently Asked Questions
What are the primary challenges of code optimization for HPC?
- Complex Code Structure: HPC applications often involve intricate code with numerous dependencies and interconnections, making optimization challenging.
- Hardware Heterogeneity: HPC systems comprise diverse hardware architectures, including CPUs, GPUs, and accelerators, requiring code optimization tailored to specific platforms.
- Data Locality: Efficient data management is crucial in HPC, as minimizing data movement and maximizing data locality can significantly improve performance.
Why is it important to optimize code for HPC?
- Reduced Execution Time: Optimization techniques can drastically reduce the execution time of HPC applications, allowing researchers and engineers to obtain results more quickly.
- Increased Resource Utilization: Optimizing code enables more efficient use of HPC resources, leading to cost savings and improved throughput.
- Improved Accuracy and Reliability: Well-optimized code minimizes errors and ensures reliable results, which is essential for scientific and engineering applications.
Top Subtopics
Memory Management
- Data Structures: Selecting appropriate data structures (e.g., arrays, linked lists) optimized for HPC platforms can improve performance.
- Memory Allocation: Efficient memory allocation techniques, such as memory pools and pre-allocation, can minimize overhead and enhance code performance.
- Memory Hierarchy: Understanding the memory hierarchy (e.g., cache levels) and optimizing data access patterns can significantly improve memory performance.
- Data Alignment: Proper alignment of data structures can optimize memory access and reduce cache misses, improving code execution speed.
Vectorization
- SIMD Instructions: Utilizing SIMD (Single Instruction Multiple Data) instructions allows processors to perform multiple operations concurrently, enhancing performance.
- Vectorization Intrinsics: Using vectorization intrinsics provided by compilers or libraries can explicitly control vectorization and improve code efficiency.
- Loop Unrolling: Unrolling loops can improve performance by reducing branch penalties and increasing instruction-level parallelism.
- Data Prefetching: Prefetching data into cache before it is needed can reduce memory latency and improve vectorization performance.
Concurrency and Parallelism
- Thread Management: Managing threads effectively can optimize code for multi-core processors and improve scalability.
- Synchronization Primitives: Properly synchronizing threads using efficient synchronization primitives (e.g., mutexes, barriers) is crucial for avoiding race conditions and deadlocks.
- Data Partitioning: Dividing data into smaller chunks and distributing it across multiple threads can enhance parallelism and improve performance.
- Load Balancing: Ensuring balanced workload distribution among threads optimizes resource utilization and minimizes performance bottlenecks.
Numerical Libraries
- Choosing the Right Library: Selecting appropriate numerical libraries optimized for HPC platforms can significantly improve performance.
- Understanding Library Interfaces: Familiarity with the interfaces and functionality of numerical libraries is essential for efficient code optimization.
- Exploiting Library Features: Utilizing advanced features provided by numerical libraries, such as optimized routines and parallel algorithms, can further enhance code performance.
- Customizing Library Functions: In some cases, modifying or customizing library functions can be beneficial for specific HPC applications.
Debugging and Profiling
- Performance Analysis Tools: Using performance analysis tools to identify performance bottlenecks and optimize code is crucial.
- Profiling: Profiling code to analyze its execution time and identify areas for improvement is essential for effective optimization.
- Code Instrumentation: Instrumenting code with performance monitoring tools can provide valuable insights into code behavior and help identify performance issues.
- Debugging Techniques: Applying effective debugging techniques to identify and fix errors is crucial for ensuring code correctness and performance.
Conclusion
Optimizing code for speed is a critical aspect of high-performance computing. By addressing the challenges associated with complex code structure, hardware heterogeneity, and data locality, developers can effectively optimize their code. The subtopics discussed in this article provide a comprehensive overview of key optimization strategies, including memory management, vectorization, concurrency and parallelism, numerical libraries, and debugging and profiling. By leveraging these techniques, developers can unlock the full potential of their HPC applications, achieve optimal performance, and drive scientific and technological advancements.
Keyword Tags
- High-performance computing
- Code optimization
- Memory optimization
- Vectorization
- Parallel programming
