Data Modeling Mistakes: Designing Effective Database Schemas
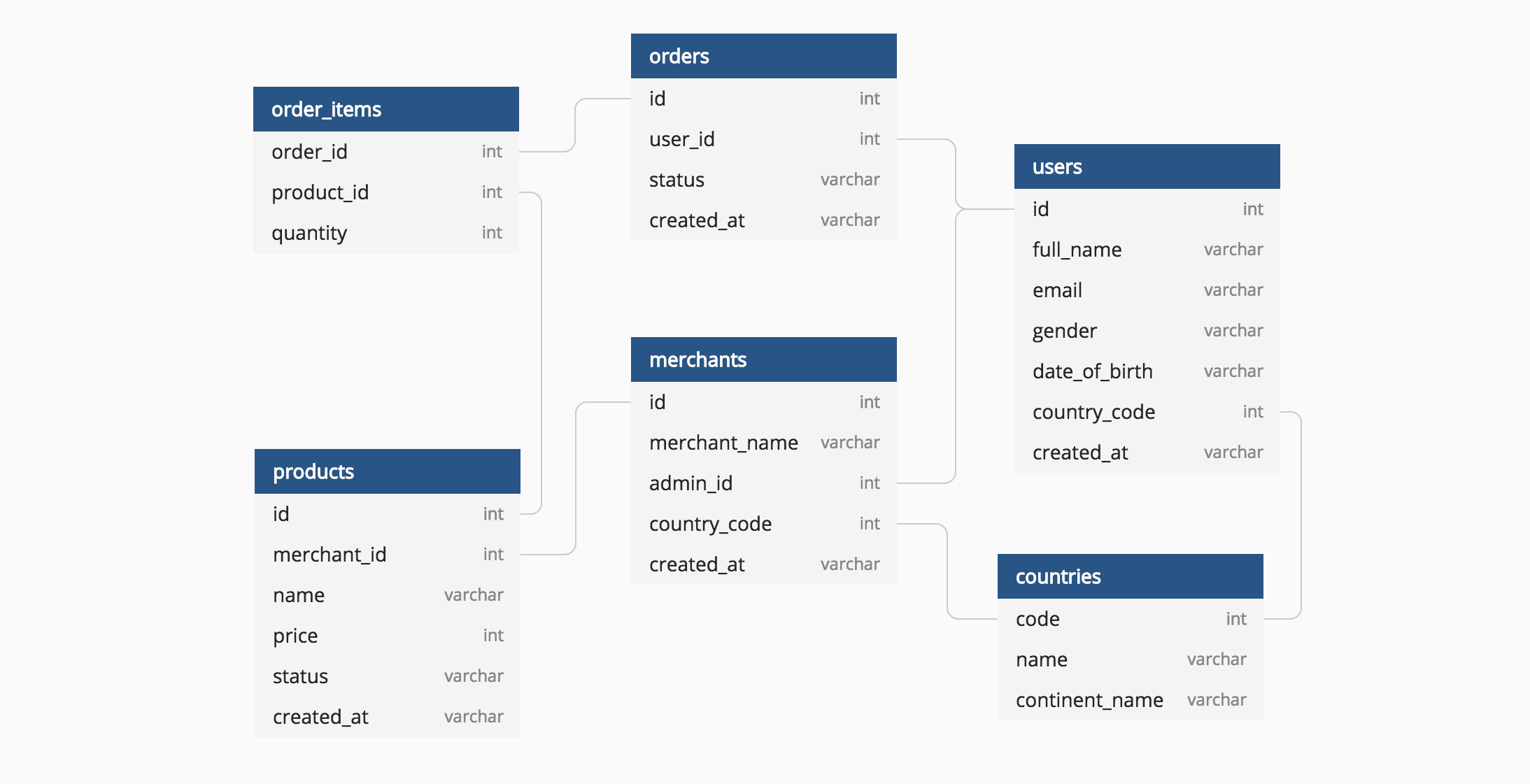
Data modeling is a critical aspect of database design that involves creating a logical representation of data to meet business requirements. However, common mistakes in data modeling can lead to inefficiencies, performance issues, and data integrity problems. Here are some common mistakes to avoid when designing effective database schemas:
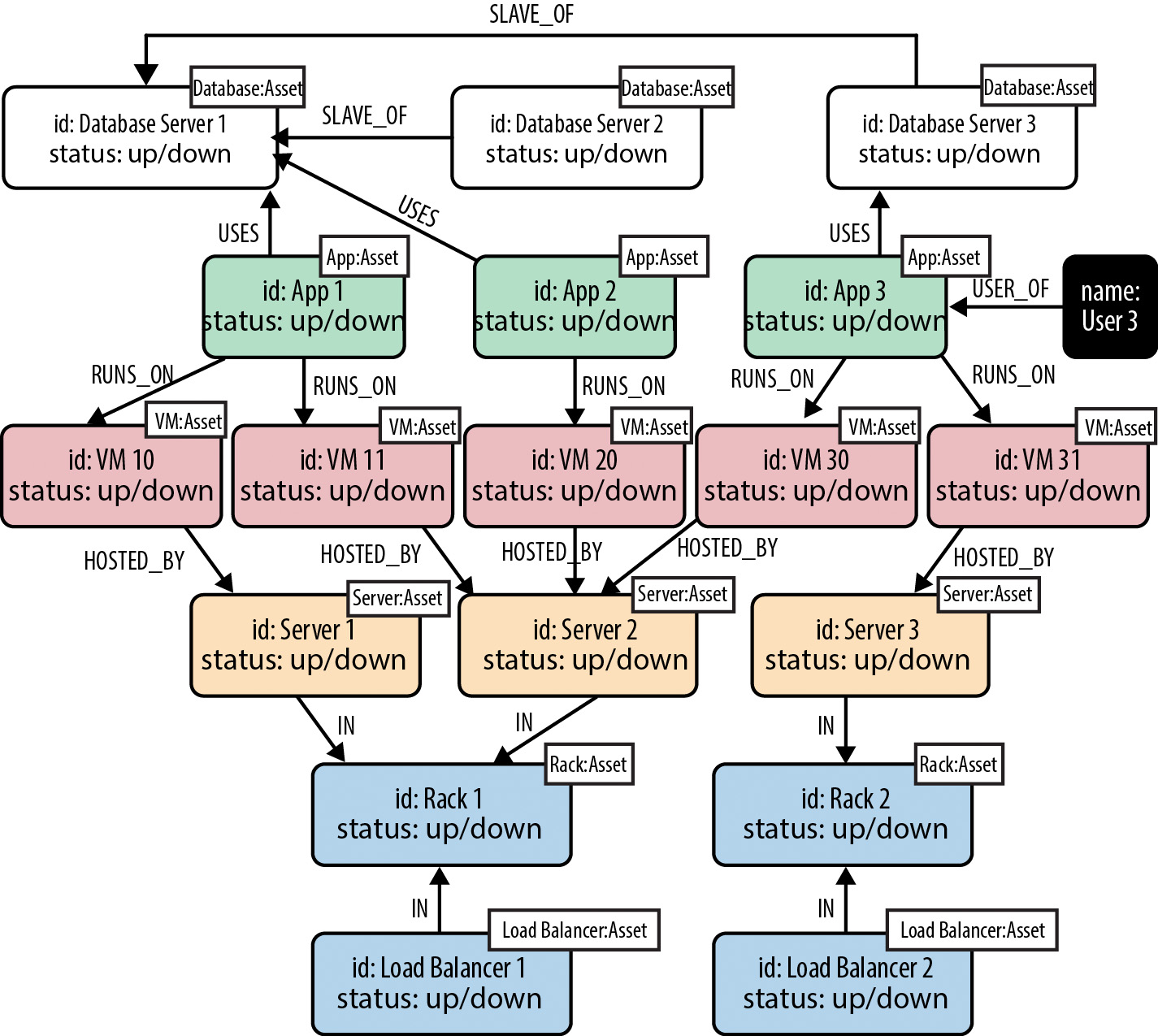
1. Lack of Conceptual Data Model:
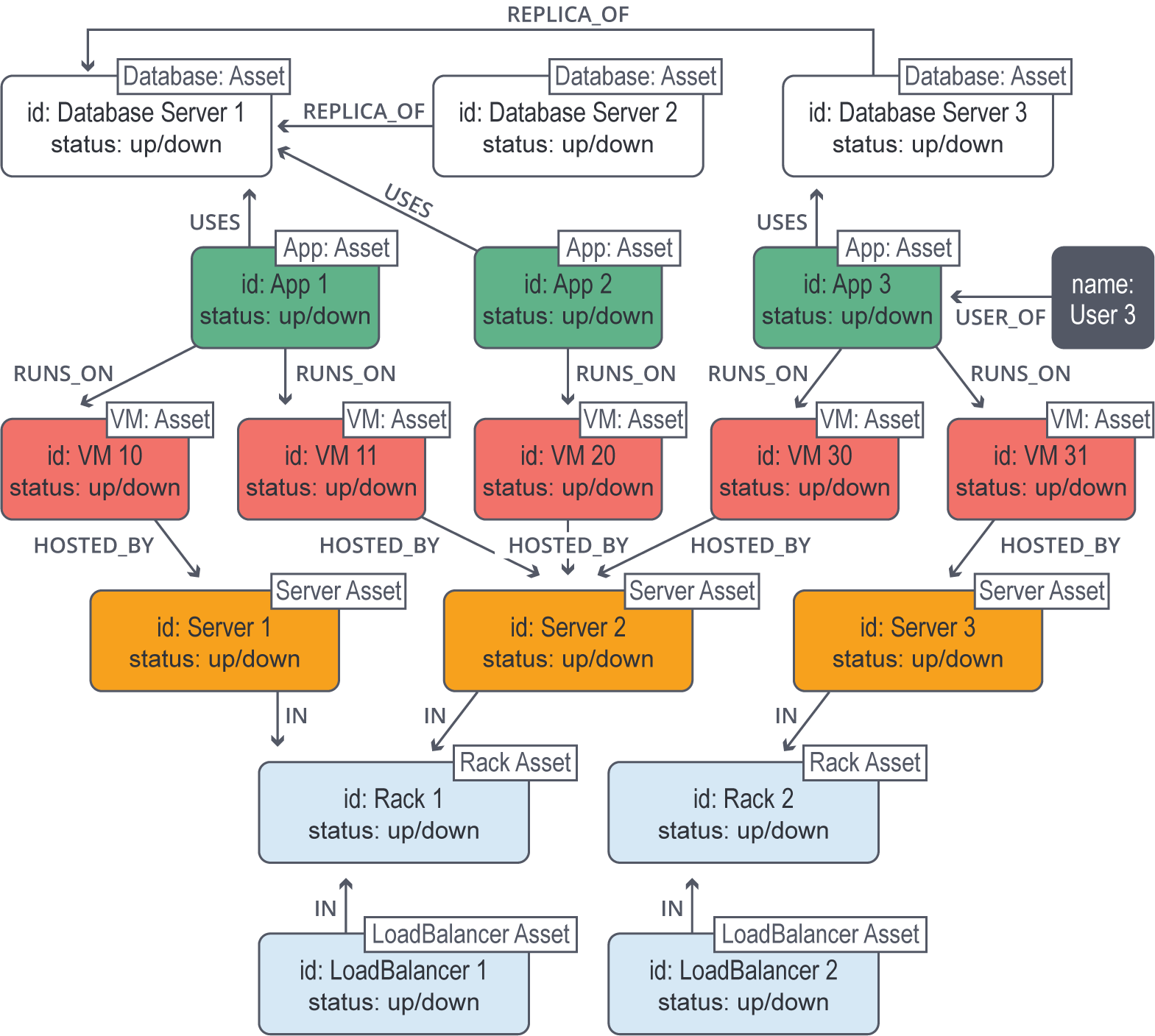
Failing to create a conceptual data model before transitioning to a physical schema can result in a disjointed and incomplete database design. A conceptual data model provides a high-level overview of the business entities, their relationships, and the data that needs to be stored.
2. Over-normalization:
Normalizing data to the Boyce-Codd normal form (BCNF) can lead to excessive table divisions, resulting in performance inefficiencies. Over-normalization should be avoided when the benefits of data integrity do not outweigh the drawbacks of increased join operations.
3. Inadequate Relationship Modeling:
Poor relationship modeling, such as not identifying the correct cardinality or referential integrity rules, can lead to data inconsistencies and errors. Ensure that relationships are accurately represented, and consider using foreign key constraints and other data integrity mechanisms.
4. Complex Data Types:
Using complex data types, such as arrays or nested tables, can increase storage requirements and make data management more difficult. Consider carefully whether these data types are necessary and explore alternative modeling options.
5. Poor Field Naming and Definition:
Ambiguous or inconsistent field names and definitions can lead to confusion and errors in data retrieval and manipulation. Use descriptive and meaningful field names, and provide clear definitions to ensure data clarity.
6. Redundant Data:
Storing duplicate data in multiple tables can cause data inconsistencies and increase storage overhead. Identify and eliminate redundant data by establishing relationships and using appropriate normalization techniques.
7. Lack of Data Validation:
Neglecting data validation rules can lead to data inaccuracies and integrity issues. Implement constraints, check conditions, and other data validation mechanisms to ensure that data entered into the database meets business requirements.
8. Insufficient Scalability:
Not considering scalability during schema design can limit the database’s ability to handle increasing data volumes and user concurrency. Design schemas with flexibility in mind, allowing for table partitioning, indexing, and denormalization when necessary.
9. Inadequate Documentation:
Lack of documentation makes it difficult for others to understand the database schema and its intended use. Provide clear documentation that outlines the data model, table structures, relationships, and any assumptions made during the design process.
10. Not Considering Performance:
Designing a schema without considering performance implications can lead to slow queries and bottlenecks. Optimize table structures, create indexes, and implement appropriate storage mechanisms (such as SSDs) to enhance database performance.## Data Modeling Mistakes: Designing Effective Database Schemas
Executive Summary
Data modeling is a foundational aspect of database design, laying the blueprint for how data is structured, organized, and accessed. Unfortunately, common mistakes in data modeling can lead to data inconsistencies, performance issues, and operational challenges. This article examines some of the gravest data modeling mistakes and provides guidance on creating effective and efficient database schemas.
Introduction
Data modeling is the process of translating business requirements into a logical representation of data structures. It involves identifying the entities, attributes, and relationships necessary to support business processes and queries. When done correctly, data modeling enables seamless data management, efficient data retrieval, and enhanced data analysis.
Common Data Modeling Mistakes
1. Overlooking Entity Relationships
- Failing to identify all relevant relationships between entities
- Assuming entities are always independent
- Neglecting to handle relationships with multiplicity constraints
2. Inconsistent Data Types and Constraints
- Allowing inconsistent data types for similar attributes
- Omitting mandatory fields or setting improper data constraints
- Failing to enforce data integrity rules, leading to data anomalies
3. Excessive Normalization
- Over-normalizing data into multiple tables, increasing data redundancy
- Introducing unnecessary complexity and performance overhead
- Making data retrieval and manipulation cumbersome
4. Poor Denormalization
- Denormalizing data without proper consideration of performance trade-offs
- Creating data redundancies that lead to inconsistencies and maintenance issues
- Failing to strike a balance between normalization and denormalization
5. Ignoring Performance Considerations
- Not designing schemas for index efficiency and query optimization
- Failing to consider data volume and distribution requirements
- Neglecting to implement appropriate indexing strategies
Conclusion
Data modeling is an indispensable step in database development. Avoiding the common mistakes discussed in this article is crucial for designing effective and efficient database schemas. By following these guidelines, organizations can ensure data integrity, improve performance, and facilitate seamless data management.
Keyword Tags
- Data Modeling
- Database Schema Design
- Data Normalization
- Denormalization
- Data Integrity
